이 글에서는 프로젝트를 진행하면서 겪은 동시성 문제와 이를 해결한 과정을 기록하고자 한다.
주식 투자 시뮬레이션 프로젝트를 진행하는 과정에서, 나는 특정 주식에 대한 매도와 매수 기능을 구현해야했다.
@RequiredArgsConstructor
@Service
public class TradeService {
private final TradeTraceService traceService;
private final MemberRepository memberRepository;
private final AccountRepository accountRepository;
private final StockService stockService;
@Transactional
public boolean trade(String memberEmail, TradeRequestDto dto, TradeConstructor tradeConstructor, TradeType tradeType) {
Member member = memberRepository.getMemberByEmail(memberEmail);
Stock stock = stockService.getStock(dto.stockCode());
Account account = accountRepository.findByMember(member)
.orElseThrow(IllegalArgumentException::new);
//거래 타입(매수 or 매도)에 맞는 거래 Trade 생성
Trade trade = tradeConstructor.createTrade(stock.getName(), dto.stockCode(), dto.quantity());
//거래 진행
trade.proceed(account, stock.getPrice());
//거래 기록
traceService.recordTrace(account, stock, dto.quantity(), tradeType);
return true;
}
}
위 코드가 매도와 매수를 담당하는 로직이다.
짧게 설명하고 지나가자면 특정 Member를 조회한 뒤 해당 Member를 통해 Account를 조회한 뒤 조회된 Account를 대상으로 매수 혹은 매도를 진행한다.
이러한 거래 기능인 trade 메서드는 실제로 계좌의 돈을 차감하거나 차증하는 중요한 메서드로, 한 사람이 동시에 여러번 거래 요청을 하더라도 모든 거래 요청은 반드시 정상적으로 실행되어야 한다.
따라서 동시에 같은 Account에 대해서 여러개의 거래 요청을 진행하는 테스트를 진행해보았다.
@SpringBootTest
public class AccountTest {
//테스트를 위한 의존성들
.
.
.
.
//동시 요청 수
private final int threadCount = 10;
@Test
public void 동시성_테스트() throws InterruptedException {
// 멀티 스레드 테스트 환경 구축
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
CountDownLatch latch = new CountDownLatch(threadCount);
// 테스트 용 DTO 생성
TradeRequestDto dto = new TradeRequestDto(testCode, 1);
//테스트 실행
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
System.out.println("Thread " + Thread.currentThread().getId() + " is attempting to acquire lock.");
//요청 보내기
tradeService.trade("test@test.com", dto, TradeConstructor.BUY, TradeType.BUY);
// 오류 및 로그 확인
System.out.println("Thread " + Thread.currentThread().getId() + " successfully acquired lock and completed the trade.");
} catch (CannotAcquireLockException e) {
System.out.println("Thread " + Thread.currentThread().getId() + " could not acquire lock: " + e.getMessage());
} catch (NoSuchElementException e) {
System.out.println("Thread " + Thread.currentThread().getId() + " NoSuch " + e.getMessage());
} catch (Exception e) {
System.out.println("Thread " + Thread.currentThread().getId() + " encountered an unexpected error: " + e.getMessage());
} finally {
latch.countDown();
}
});
}
//결과 확인
Member member = memberRepository.getMemberByEmail("test@test.com");
account = accountRepository.findById(1L).orElseThrow();
long actual = account.getMoney();
assertEquals(testAccountMoney - threadCount * testStockPrice, actual);
assertEquals(1, account.getHasTrades().size());
}
// DB 롤백
@AfterEach
public void cleanUp() {
tradeTraceRepository.deleteAll();
memberRepository.deleteAll();
accountRepository.deleteAll();
}
}
테스트 코드가 상당히 길지만 사실 별 내용은 없다.
여러개의 스레드를 사용할 수 있는 Java의 ExecutorService라이브러리를 사용하여 여러개의 스레드로 동시에 같은 Account에 대해서 거래 요청을 보내본 후, Account의 잔액과 보유 주식 수가 제대로 변경되었는지 확인한 후,
@AfterEach를 사용해서 DB를 지워주는 방식이다.
여기서 한가지 의문점이 있을 수 있다.
왜 Test 코드에서 @AfterEach를 사용해서 실제 DB에 대한 데이터를 지우는가? 그냥 @Transactional을 사용해서 test 롤백을 하면 되는거 아닌가라고 생각할 수 있다.
나도 그렇게 생각했기 때문이다.
하지만, @Transactional을 사용하는 Test 코드에는 한계가 있었다.
@Transactional의 test 데이터 롤백 기능은 단일 스레드에서만 작동을 한다, ExecutorService라이브러리를 사용해서 다중 스레드로 테스트를 진행하는 내 코드에서는 이 @Transactional이 내가 원하는대로 데이터를 롤백 시켜주지 않았다.
따라서 나는 @AfterEach를 사용해서 직접 데이터베이스의 데이터를 삭제시켜 주었다.
또한 @AfterEach를 통해 데이터를 지우는 방식은 결국 테스트 코드에서 실제 DB에 접근하여 영향을 준다는 의미인데, 테스트 코드는 절대 실제 DB에 영향을 주어서는 안된다.
따라서 나는 테스트용 DB를 따로 만들어주었다.
Test용 DB를 따로 만드는 방법은 간단하다, MySQL에서 데이터베이스를 하나 새로 만들어준 다음
프로젝트의 \src\test\resources 폴더에 새로운 application.properties를 추가하여 작성하면, test용 application.properties로 설정이 된다.
#mysql
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/stock-simul-test?useSSL=false&allowPublicKeyRetrieval=true&useUnicode=true&rewriteBatchedStatements=true&serverTimezone=Asia/Seoul
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQLDialect
spring.datasource.username=😂
spring.datasource.password=😂
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.properties.hibernate.jdbc.batch_size=100
spring.jpa.properties.hibernate.order_inserts=true
spring.jpa.properties.hibernate.order_updates=true
spring.sql.init.mode=always
#firebase
firebase-realtime-database.database-url=https://stock-simul-aeb30-default-rtdb.firebaseio.com/
firebase-realtime-database.database-name=stocks
위의 파일이 내가 test용 resource안에 작성한 application.properties이다.
2번째 줄을 보면, 연결된 DB가 stock-simul-test 라는 이름으로 된걸 확인할 수 있다.
이렇게 설정을 한뒤에는 텅 비어있는 test용 DB에 test에 필요한 데이터 테이블들을 추가해주어야 한다.
똑같이 test의 resource안에 sql 파일을 하나 작성해주고 위의 applications.properties의 #mysql 마지막 줄을 보면 spring.sql.init.mode=always 인걸 볼 수 있는데, 이를 설정해두면 테스트가 실행될 때 마다 자동으로 resource안의 sql파일이 실행이 된다.
sql 파일을 아래처럼 작성했다.
CREATE TABLE IF NOT EXISTS `Account`
(
`id` BIGINT AUTO_INCREMENT PRIMARY KEY,
`money` BIGINT NOT NULL,
`member_id` BIGINT
);
CREATE TABLE IF NOT EXISTS `Member`
(
`id` BIGINT AUTO_INCREMENT PRIMARY KEY,
`nick_name` VARCHAR(255),
`email` VARCHAR(255),
`password` VARCHAR(255),
`account_id` BIGINT,
CONSTRAINT `fk_member_account`
FOREIGN KEY (`account_id`)
REFERENCES `Account` (`id`)
ON DELETE SET NULL
);
CREATE TABLE IF NOT EXISTS `Account_trades`
(
`account_id` BIGINT NOT NULL,
`stock_name` VARCHAR(255),
`stock_code` VARCHAR(255),
`quantity` INT NOT NULL,
CONSTRAINT `fk_account_trades_account`
FOREIGN KEY (`account_id`)
REFERENCES `Account` (`id`)
ON DELETE CASCADE
);
INSERT INTO `Account` (`id`, `money`, `member_id`) VALUES (1, 1000000, NULL);
INSERT INTO `Member` (`id`, `nick_name`, `email`, `password`, `account_id`) VALUES (1, 'test', 'test@test.com', 'testpw', 1);
UPDATE `Account` SET `member_id` = 1 WHERE `id` = 1;
이렇게 하면 이제 테스트를 위한 DB 생성이 끝이났고, @Transactional을 사용하지 않고도 test 데이터 롤백을 시킬 수 있게 되었다.
테스트 환경을 갖춘 후 바로 테스트를 진행해보았더니

10개의 요청이 들어갔기 때문에 잔액이 (10 * 주식 가격) 만큼이 빠져야 하지만, 하나의 요청 가격만이 빠진걸 볼 수 있었다.
어째서 이런 상황이 발생한건지 고민을 해보았는데,
@RequiredArgsConstructor
@Service
public class TradeService {
private final TradeTraceService traceService;
private final MemberRepository memberRepository;
private final AccountRepository accountRepository;
private final StockService stockService;
@Transactional
public boolean trade(String memberEmail, TradeRequestDto dto, TradeConstructor tradeConstructor, TradeType tradeType) {
Member member = memberRepository.getMemberByEmail(memberEmail);
Stock stock = stockService.getStock(dto.stockCode());
Account account = accountRepository.findByMember(member)
.orElseThrow(IllegalArgumentException::new);
Trade trade = tradeConstructor.createTrade(stock.getName(), dto.stockCode(), dto.quantity());
trade.proceed(account, stock.getPrice());
traceService.recordTrace(account, stock, dto.quantity(), tradeType);
return true;
}
}
해당 trade 라는 메서드를 통해 거래 요청이 처리되는데, 하나의 요청이 Account에 대한 잔액을 변경하고 커밋하여 DB에 반영하기 전에, 다른 스레드들까지 들어와서 변경되지 않은 Account, 즉 언두영역을 읽어버리면서, 이러한 상황이 발생했던 것이다.
나는 이 동시성 문제를 해결하기 위해서, 비관적 Lock을 사용했다.
비관적 락 또는 Pessomistic Lock이란 데이터의 동시성 문제를 막기위한 해결방안중 하나이다.
기본적으로 이 비관적 락은 낙관적 락(Optimistic Lock)과 함께 설명된다.
비관적 락과 낙관적 락에 대해 가볍게 알아보자면,
두 Lock 모두 Transaction 단위에서 발생하는 데이터의 동시성 문제를 해결하기 위해 사용되는 방법으로,
비관적 Lock의 경우에는 DB 레벨에서 데이터의 row 단위로 Lock을 걸어버림으로써, 동시성 문제를 방지하는 방식이며,
낙관적 Lock의 경우에는 DB 레벨이 아닌 Application레벨에서 별도의 Lock없이 동시성 문제를 방지하는 방법이다.
간단하게 정리하자면
비관적 Lock (Pessmisitic Lcok)
- DB레벨에서 row 단위로 Lock
- shared Lock (읽기 락), exclusive Lock (쓰기 락) 둘 다 가능
- select for update 쿼리 발생 (exclusive Lock 한정)
- 동시성 문제가 발생할 것이라 생각 될 때 주로 사용
- 동시성 문제를 사전에 방지
- 동시 접근이 많을 경우 스레드들의 대기 시간 증가 -> 성능 저하
낙관적 Lock (Optimistic Lock)
- Application 레벨에서 잡아주는 Lock 방식
- 별도로 진짜 Lock을 걸지는 않음
- Version을 사용하여 데이터의 무결성을 유지
- 동시성 문제가 발생하지 않을 것이라고 생각하며 사용
- 별도의 Lock이 없기 때문에 동시성 문제 발생시 Rollback
- 잦은 동시성 문제 발생 -> 잦은 롤백 -> 성능 저하
나는 왜 비관적 Lock을 사용했고, 비관적 Lock이 뭔지 자세한 부분에 대해서는 해당 이슈 PR에 올려두었다
https://github.com/piedra-de-flor/stock-simulation/pull/16
trade 메서드에서의 동시성 문제 이유로 AccountRepository에 비관적 Lock 추가 by piedra-de-flor · Pull Request
기존의 문제점 Account의 trade가 같은 요청으로 동시에 여러개가 들어왔을 때, Member의 getAccount()를 여러 스레드가 동시에 수행하면서 요청이 하나씩 순차적으로 수행되는게 아닌 여러 스레드가 같
github.com
따라서 AccountRepository 에 비관적 락을 추가해주었더니
public interface AccountRepository extends JpaRepository<Account, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT a FROM Account a WHERE a.member = :member")
Optional<Account> findByMember(Member member);
}
결과는 똑같았다.....
비관적 Lock을 명시적으로 걸어줬음에도 정상적으로 작동하지 않는 내 상황은 말 그대로 멘붕이었다.
따라서 나는 프로덕션 코드에 log를 넣어서 Lock이 제대로 걸리고 있는건지, 현재 여러 스레드들의 요청을 어떻게 처리하고 있는지를 확인해보았다.
비관적 Lock을 걸게되면 MySQL을 기준으로 조회를 할 때 select for update 쿼리가 발생하게 되면서, 해당 데이터 row 단위에 접근할 수 없도록 Lock이 걸리게 되어 있다.
나는 먼저 select for update 쿼리가 제대로 발생하는지 부터 확인하였다.
Hibernate:
select
a1_0.id,
a1_0.money
from
account a1_0
join
member m1_0
on a1_0.id=m1_0.account_id
where
m1_0.id=? for update
정확하게 select for update쿼리는 발생하고 있었다.
하지만 하나 걸리는게 있다면, 10개의 스레드가 모두 동시에 select for update 쿼리를 날리는 것이다.
Hibernate:
select
a1_0.id,
a1_0.money
from
account a1_0
join
member m1_0
on a1_0.id=m1_0.account_id
where
m1_0.id=? for update
Hibernate:
select
a1_0.id,
a1_0.money
from
account a1_0
join
member m1_0
on a1_0.id=m1_0.account_id
where
m1_0.id=? for update
Hibernate:
select
a1_0.id,
a1_0.money
from
account a1_0
join
member m1_0
on a1_0.id=m1_0.account_id
where
m1_0.id=? for update
.......
분명 select for update 쿼리문으로 인해 해당 데이터에 대해 row 단위 Lock이 걸렸을 텐데, 왜 다른 스레드들이 해당 데이터를 읽어올 수 있는지 의문이었다.
현재의 테스트 상으로는 여러 스레드들이 비관적 Lock이 걸린 데이터를 읽어올 뿐, update에 대해서는 Lock이 제대로 작동하여, 순차적으로 진행되고 있었다.
하지만 Account의 잔액이 변경되기 전의 데이터를 읽어오다 보니 모든 스레드들이 1,000,000원이라는 잔액에서 test용 주식 가격을 뺀 상태로 업데이트를 진행하고 있었다. 즉, 10개 모든 요청이 Account의 잔액을 1,000,000원에서 939,700원으로 변경중인 것이었다.
그럼 뭐가 문제일까,
사실 이 문제로 5일은 삽질한것 같다...
transaction 전파 범위 부터 MySQL 격리수준, MySQL 공식문서, 비관적 락 읽기 오류, StackOverflow등 안찾아본 정보가 없을 정도로 정말 해결하고 싶었고, 노력했다.
결론적으로 문제는 DB 측면의 트랜잭션범위나, 비관적 Lock에서 발생한게 아니었다.....
문제는 Member와 Account의 1:1 매핑이 문제였다.
@RequiredArgsConstructor
@Service
public class TradeService {
private final TradeTraceService traceService;
private final MemberRepository memberRepository;
private final AccountRepository accountRepository;
private final StockService stockService;
@Transactional
public boolean trade(String memberEmail, TradeRequestDto dto, TradeConstructor tradeConstructor, TradeType tradeType) {
Member member = memberRepository.getMemberByEmail(memberEmail);
Stock stock = stockService.getStock(dto.stockCode());
Account account = accountRepository.findByMember(member)
.orElseThrow(IllegalArgumentException::new);
Trade trade = tradeConstructor.createTrade(stock.getName(), dto.stockCode(), dto.quantity());
trade.proceed(account, stock.getPrice());
traceService.recordTrace(account, stock, dto.quantity(), tradeType);
return true;
}
}
trade 메서드는 먼저 email을 통해 Member 객체를 먼저 불러오고, 그 다음 Account 객체를 불러오게 되어있다.
하지만 Member 클래스를 보면
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
@Entity
public class Member implements UserDetails {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
private String nickName;
private String email;
private String password;
@ElementCollection(fetch = FetchType.EAGER)
private List<String> roles = new ArrayList<>();
@OneToOne
@JoinColumn(name = "account_id")
private Account account;
@Builder
public Member(String name, String email, String password, List<String> roles) {
this.nickName = name;
this.email = email;
this.password = password;
this.roles = roles;
}
이렇게 Account와 1:1 매핑 관계가 되어 있는걸 확인 할 수 있다.
구글링을 해보니 JPA에서는 1:1 연관관계 매핑의 경우 지연로딩(Lazy loading)이 아니라 즉시 로딩(Eager loading)을 사용해서 데이터를 가져온다는걸 찾아볼 수 있었다...
Spring을 많이 사용해 봤거나 공부해본 사람이라면 JPA의 1차 캐시를 들어는 봤을 것이다.
JPA가 기본적으로 DB에서 데이터를 조회해오는 과정은 다음과 같다.
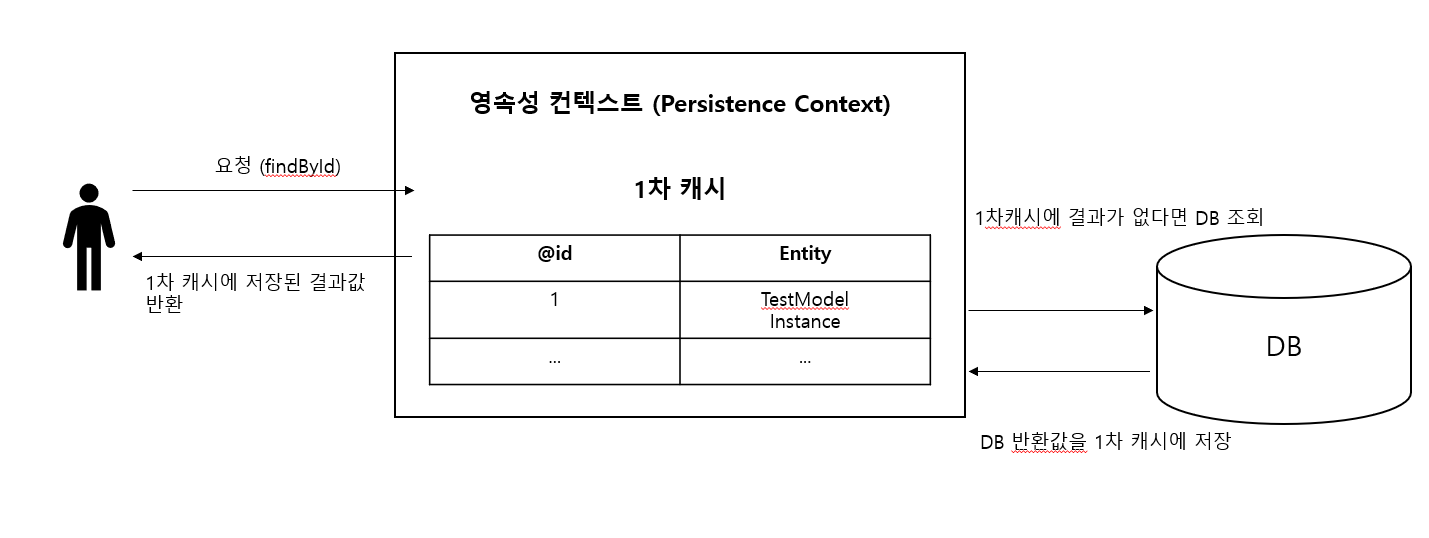
JPA는 먼저 데이터를 조회할 때, 영속성 컨텍스트 안의 1차 캐시를 조회한다. 그 후 1차 캐시에 원하는 데이터가 없을 시에만 실제 DB에 접근해서 조회를 해오고, 만약 1차 캐시에 데이터가 이미 로드 되어 있다면 DB에 따로 쿼리를 날리지 않고 1차 캐시에서 들고온다.
따라서 나의 trade 메서드에서 Member를 먼저 가져오면서, Member와 1:1 연관관계 매핑이 되어 있는 Account가 함께 가져와지고, JPA를 사용하기 때문에 Account 객체가 1차 캐시에 로드되어 있었던 것이다. (정확히는 2차 캐시)
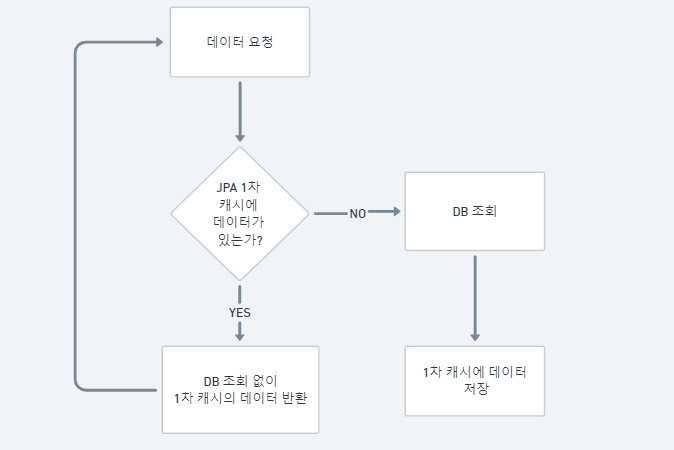
위의 그림 흐름대로 JPA가 데이터 조회를 처리하는데, 나의 경우 10개의 동시 요청을 보내면, 가장 처음으로 실행되는 요청만 분기문에서 NO가 되고, 그 다음으로 들어오는 요청들은 전부 YES로 분기됙 때문에, 10개의 동시 요청을 보내도 1개의 요청만 실행된 것처럼 보였던 것이다.
그래서 10개의 스레드들이 요청을 select for update로 보내도 비관적 Lock은 DB 측면에서의 Lock이지, JPA는 DB에 직접 접근하여 찾기보다 먼저 1차 캐시에서 해당 데이터를 찾아보기 때문에 조회가 가능했던 것이었다.
( 1차 캐시에서 가져오는거면서 DB에 select for update 쿼리는 왜 보내졌는지가 의문...)
따라서 나는 Member에 대한 Account 1:1 연관관계 매핑의 로드 방식으로 Lazy로 변경해주었고,
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
@Entity
public class Member implements UserDetails {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
private String nickName;
private String email;
private String password;
@ElementCollection(fetch = FetchType.EAGER)
private List<String> roles = new ArrayList<>();
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "account_id")
private Account account;
@Builder
public Member(String name, String email, String password, List<String> roles) {
this.nickName = name;
this.email = email;
this.password = password;
this.roles = roles;
}
다시 테스트를 돌려본 결과는 정상적으로 처리되었다.

.
이렇게 내가 프로젝트에서 잔액에 대한 동시성 문제를 해결한 과정이었다.
이처럼, 동시성 문제는 잔액 뿐만 아니라 데이터를 업데이트하는 모든 Transaction에서 발생할 수 있는 문제이다.
많은 사람들이 동시성 문제를 겪고, 이를 해결하는 과정에 대해 많은 글이 있지만, 나와 같이 Lock을 적용해도 안되는 경우가 있다는 걸 알아두었으면 한다.
만약 비관적 Lock을 걸었음에도, 다른 스레드에서 조회가 가능하다면 해당 엔티티의 연관관계를 먼저 확인해보는것도 좋을것 같다...
이 외에도 Lock은 DB의 Transaction 격리 수준이나, DB 설정 혹은 프로젝트 설정등으로 인한 오류로 제대로 작동하지 않는 경우도 있다고 하니, 만약 연관관계 매핑도 체크했지만 Lock이 제대로 실행되지 않는다면, 이러한 문제가 있는건 아닌지 확인해보길 바란다.
'백엔드 멘토링' 카테고리의 다른 글
| [회고록] Nomadic 프로젝트 API 완성도 기록지 (3) | 2024.09.28 |
|---|---|
| 주식 투자 프로젝트 실시간 Real time DB 적용기 (9) | 2024.09.06 |
| 객체지향적 Refactoring 과정의 기록 (1) | 2024.07.11 |
| 순환 참조를 해결해보기 (0) | 2024.02.28 |
| 좋아요 기능 성능 개선해보기 (2) (0) | 2024.02.22 |