이 포스팅은 여행 서비스 프로젝트인 nomadic의 조회 성능 과정 일지입니당.
어떤 고민을 거치고, 어떤 트러블슈팅이 있었는지, 결과는 어땠는지를 중점적으로 다룰거고,
제가 했던 고민들과 어떤 의사결정을 내렸는지, 그 과정에서 어떤 문제들이 있었고 어떻게 해결했는지 보며,
함께 생각해보고 더 나은 방법이 있다면 댓글로 알려주길 바랍니당.
트러블 슈팅을 거의 다 기록하고, 고민과정과 구현방식등 많은 내용이 포함되어 있어, 다소 장황할 수 있으나
내가 어떻게 성능 개선을 했는지 정확하게 기록하고자하는 포스팅이기에 양해 부탁드립니다 ^o^
목차
1. 성능 개선 배경
2. 성능 테스트
3. 성능 개선
4. 후기
중간중간 트러블 슈팅과 고민 과정등이 포함되어 있습니다.
성능 개선 배경
토이 프로젝트로 진행했던 Nomadic 여행 서비스의 개발을 진행하며, 여러 숙소에 대한 조회 기능을 구현했다.
숙소 정보들은 python을 사용한 웹 스크래핑을 사용하여 데이터를 가져왔으며, 현재 테스트를 위해 가져온 데이터는
약 6000개 정도이다.
숙소 Entity의 필드는 다음과 같다.
@Entity
public class Accommodation {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
private String local;
private String name;
private double score;
private String category;
private long lentDiscountRate;
private int lentTime;
private long lentOriginPrice;
private long lentPrice;
private boolean lentStatus;
private LocalTime enterTime;
private long lodgmentDiscountRate;
private long lodgmentOriginPrice;
private long lodgmentPrice;
private boolean lodgmentStatus;
보면 알다시피 많은 필드가 존재하기에, 단순한 하나의 필드를 가지고 조회를 하기보단
모든 필드를 옵션으로 걸어서 다중 조건 조회를 하는 것이 UX면에서 더 좋은 효과를 볼 수 있을 것 같았기에,
Querydsl을 사용한 동적 쿼리 생성을 적용했다.
아래의 코드는 Querydsl을 통해 동적쿼리를 생성하는 부분이다.
private BooleanExpression buildPredicate(
String local, String name, String discountRate, String startLentPrice, String endLentPrice,
String category, String score, String lentStatus, String enterTime,
String startLodgmentPrice, String endLodgmentPrice, String lodgmentStatus) {
return stringEq(QueryDslStringConditions.LOCAL.name(), local)
.and(stringIn(QueryDslStringConditions.NAME.name(), name))
.and(priceEq(startLentPrice, endLentPrice, QueryDslPriceConditions.LENT.name()))
.and(stringIn(QueryDslStringConditions.CATEGORY.name(), category))
.and(scoreGoe(score))
.and(lentStatusEq(lentStatus))
.and(enterTimeGoe(enterTime))
.and(priceEq(startLodgmentPrice, endLodgmentPrice, QueryDslPriceConditions.LODGE.name()))
.and(discountRateGoe(discountRate));
}
전체 코드는 아니지만, 이런식으로 이름별, 지역별, 가격대별, 별점별, 카테고리별, 잔여 객실 여부, 할인율 등등을 사용하며 조회를 자유롭게 할 수 있도록 구성하였다.
여기서 난 한가지 고민이 생겼다.
숙소 데이터를 지금 모두 가져온 것이 아니기에, 만약 실제 서비스를 하기 위해서는 모든 숙소 정보를 가지고 있어야 할 필요가 있다.
숙소 예약 서비스인 야놀자에서 제공하는 숙소의 개수는 약 15000개다.
만약 이정도의 데이터를 가진 상황에서 동적 쿼리를 통해 데이터를 조회하는 로직의 호출이 잦아지면 DB의 부하가 커져, 성능이 저하될 것이라 예상됐다.
이를 해결하기 위해서 여러 방법은 떠올렸다.
- 인덱싱
- Redis 캐싱
- ES 도입
이 3가지 방법 중 내게 맞는 해결방안을 선택하기 위해서는, 일단 내 상황이 어떤지, 현 상태가 어떤지 먼저 정확하게 파악해야한다.
그래서 nGrinder를 사용해서 랜덤 동적 쿼리 생성 스크립트를 통해 숙소 조회 성능 테스트를 시작했다.
성능 테스트
물론 이 과정에서도 문제가 있었다 ㅜㅜ
nGrinder의 JDK 버전 오류, nGrinder 스크립트 오류가 있었고, 그 외에도 테스트를 위해 Docker에 올려둔 웹 스크래핑 서버가 제대로 작동하지 않는 문제도 있었다.
사실 Docker에 올려둔 웹 스크래핑 서버의 오류는 맥락상 지금 상황과는 관계가 없지만, 이 오류를 해결하기 위해 삽질만 3,4일은 해서 꼭 말하고싶었다 ㅜㅜㅜㅜㅜ
결국 해결 못한건 비밀
nGrinder의 스크립트 오류와 JDK 버전 오류는 구글링이나 gpt에게 물어보면 금방 해결해 줄 수 있기 때문에 금방 해결했다!
아래는 nGrinder의 스크립트다.
import static net.grinder.script.Grinder.grinder
import net.grinder.script.GTest
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
import org.junit.Before
import org.junit.Test
import org.junit.runner.RunWith
import net.grinder.plugin.http.HTTPRequest
import HTTPClient.HTTPResponse
import java.util.Random
/**
* nGrinder를 이용한 랜덤 숙박 검색 API 테스트
*
* @author 사용자
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
private static final String TEST_URL = "http://localhost:8080/accommodations"
private static final List<String> LOCAL_LIST = ["서울", "부산", "대전", "광주", "대구", "울산", "인천", "제주", "수원"]
private static final List<String> CATEGORY_LIST = ["호텔", "모텔"]
private static final List<String> NAME_KEYWORDS = ["호텔", "모텔"]
private static final List<String> TIME_LIST = ["14:00", "15:00", "16:00", "17:00", "18:00", "19:00"]
private static final Random random = new Random()
@BeforeProcess
public static void beforeProcess() {
test = new GTest(1, "Accommodation Search API Test")
request = new HTTPRequest()
grinder.logger.info("before process: HTTPRequest 및 GTest 객체 초기화 완료.")
}
@BeforeThread
public void beforeThread() {
test.record(this, "test")
grinder.statistics.delayReports = true
grinder.logger.info("before thread: 각 스레드 초기화 완료.")
}
@Before
public void before() {
grinder.logger.info("before: 테스트 실행 준비 완료.")
}
/**
* 리스트에서 랜덤 요소 반환
*/
private String getRandomElement(List<String> list) {
return list[random.nextInt(list.size())]
}
/**
* 1/5 확률로 null, 4/5 확률로 실제 값 반환
*/
private String maybe(String value) {
return random.nextDouble() < 0.8 ? value : null
}
private int getStartPrice() {
return 1 + random.nextInt(40000)
}
private int getEndPrice() {
return 60000 + random.nextInt(940001)
}
private String getRandomScore() {
return String.format("%.1f", 1.0 + random.nextDouble() * 4.0)
}
private String getRandomBoolean() {
return random.nextBoolean() ? "1" : "0"
}
/**
* 랜덤 쿼리 파라미터 생성
*/
private String buildQueryParams() {
Map<String, String> params = [
"local" : maybe(getRandomElement(LOCAL_LIST)),
"name" : maybe(getRandomElement(NAME_KEYWORDS)),
"discountRate" : maybe("0"),
"startLentPrice" : maybe(getStartPrice().toString()),
"endLentPrice" : maybe(getEndPrice().toString()),
"category" : maybe(getRandomElement(CATEGORY_LIST)),
"score" : maybe(getRandomScore()),
"lentStatus" : maybe(getRandomBoolean()),
"enterTime" : maybe(getRandomElement(TIME_LIST)),
"startLodgmentPrice": maybe(getStartPrice().toString()),
"endLodgmentPrice" : maybe(getEndPrice().toString()),
"lodgmentStatus" : maybe(getRandomBoolean())
]
return params.findAll { it.value != null }
.collect { k, v -> "${k}=${v}" }
.join("&")
}
@Test
public void test() {
String queryParams = buildQueryParams()
String url = "${TEST_URL}?${queryParams}"
grinder.logger.info("Requesting URL: " + url)
HTTPResponse response = request.GET(url)
if (response.statusCode == 200) {
grinder.logger.info("✅ Success: " + response.text)
} else {
grinder.logger.error("❌ Error: " + response.statusCode)
}
grinder.sleep(1000)
assert response.statusCode == 200
}
}
이제 성능테스트를 할 차례인데, 성능 테스트를 할 때에는 무엇보다 목표를 명확하게 설정하는것이 중요하다.
어떤 상황에서 어느정도의 성능을 낼 수 있도록 할 것인지에 대한 목표가 명확해야한다.
목표가 명확하지 않으면 어느정도에서 성능 개선을 끝내야 하는지, 성능 개선을 잘 한건지 알 수가 없기 때문이다.
이번에 나의 성능 개선 시나리오는 총 3개이며, 각각 상황을 보고 목표를 세웠다.
위의 스크립트를 보면 마지막쯤에 grinder.sleep(1000) 이 있다.
이는 사용자가 요청을 보내는 think time으로 사용자 1명이 1초에 요청 1개를 보내도록 조절하는 코드다.
rps가 1 이므로 nGrinder의 vuser의 수가 곧 동시접속자의 수와 같다.
- 주변 친한 지인들만 서비스를 사용할 때 (rps 20 / vuser 20명)
- 서비스를 실제 배포했을 때 (rps 300 / vuser 300명)
- 서비스 이용자 과포화 상태일 때 (vuser 1000명) - ramp-up 을 사용하여 부하테스트를 줬기 때문에 rps가 1000은 아님
각각 테스트 해본 결과 아래와 같았다.
1. 동시 사용자 20명


2. 동시 사용자 300명
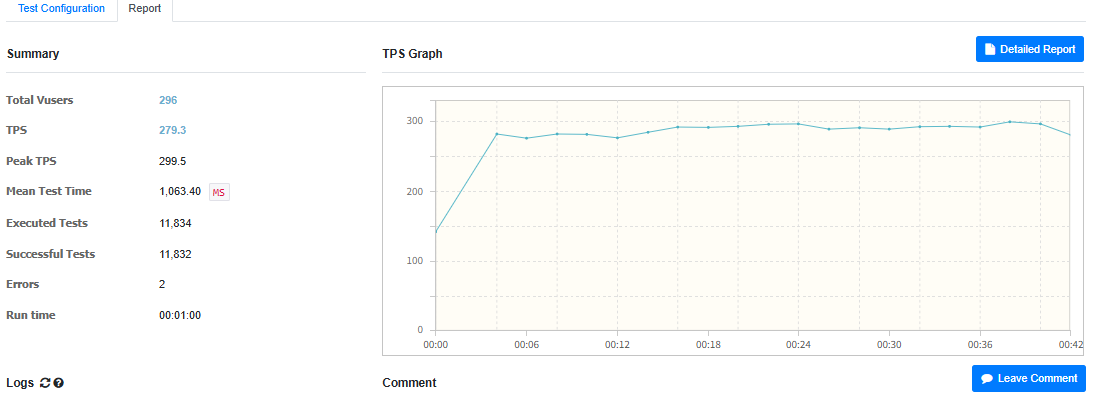
3. 동시 사용자 1000명 (Ramp-up 형식으로 부하 테스트)

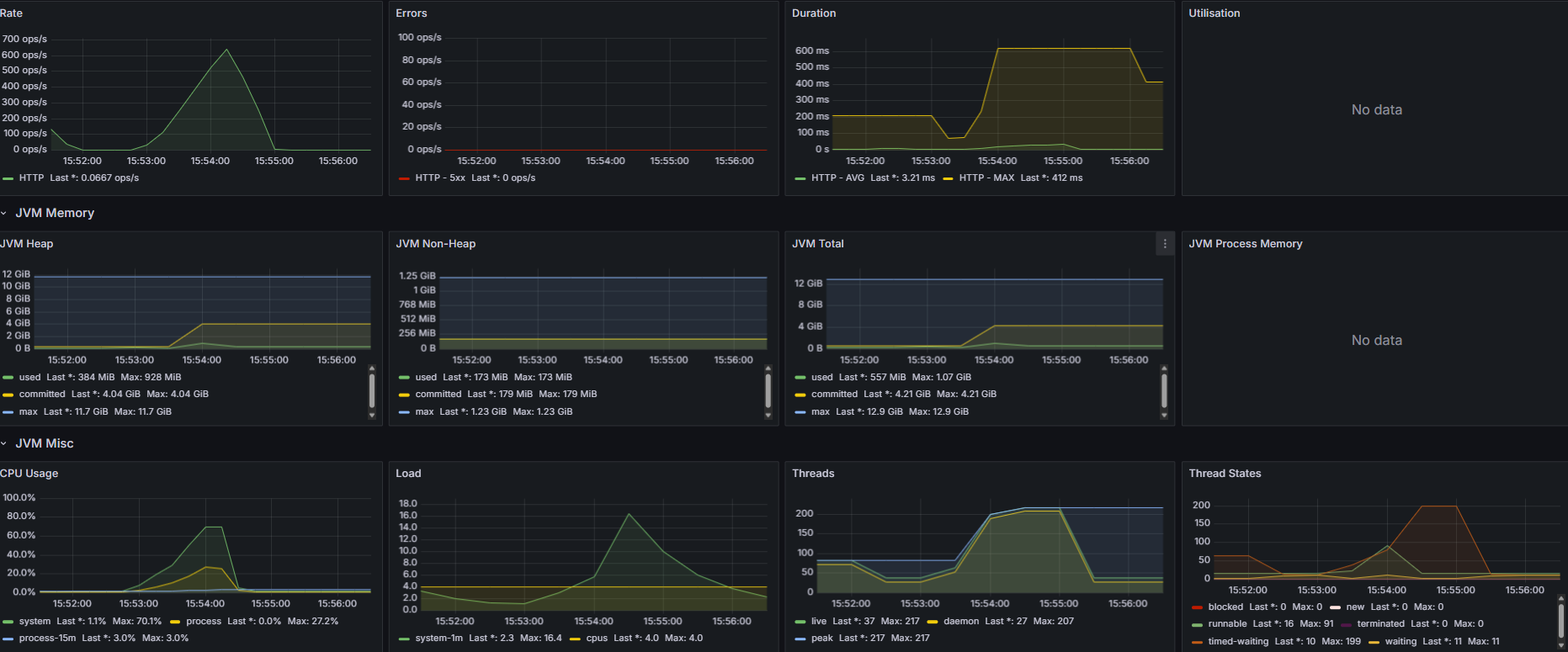
테스트 결과를 보면, 20명 300명은 잘 받아내지만 1000명을 하는 순간 어느 지점에서 모든 요청이 실패하며, 테스트가 실패하는걸 볼 수 있다.
이유가 뭘까
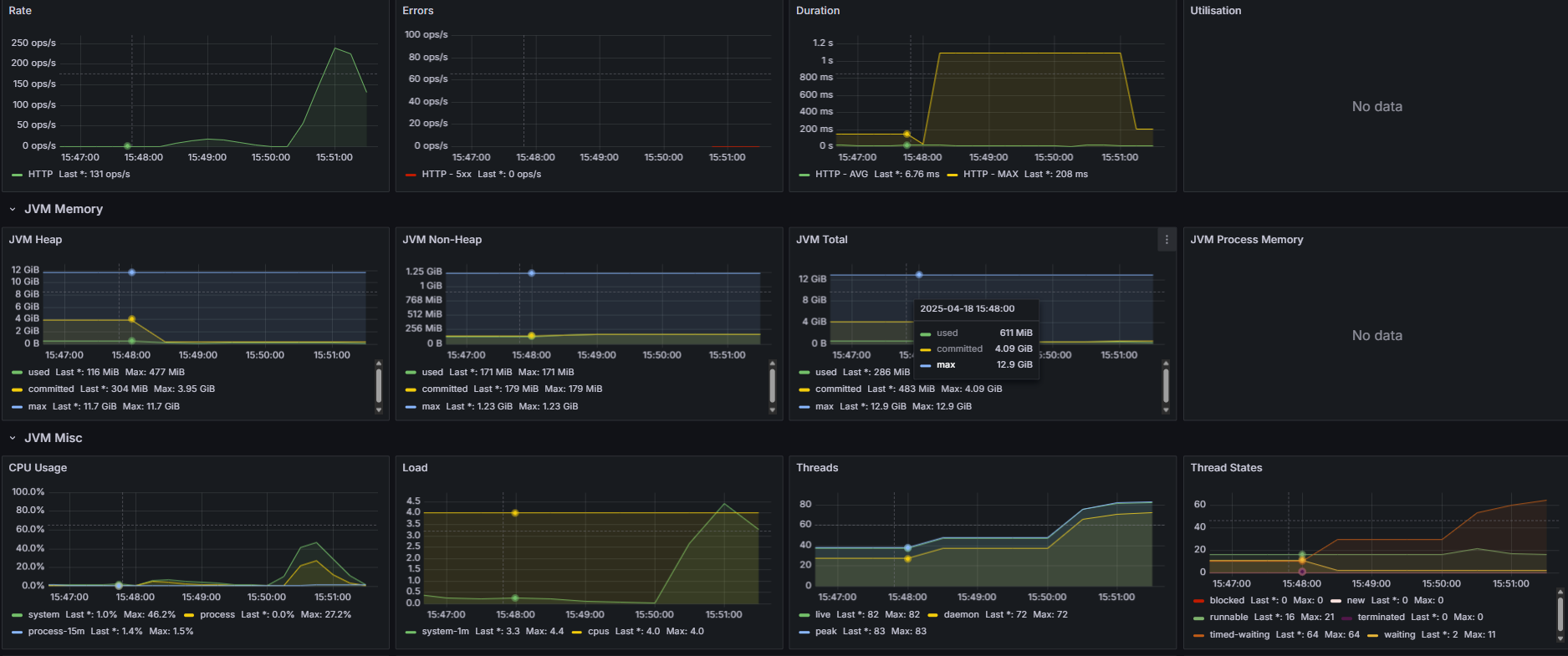
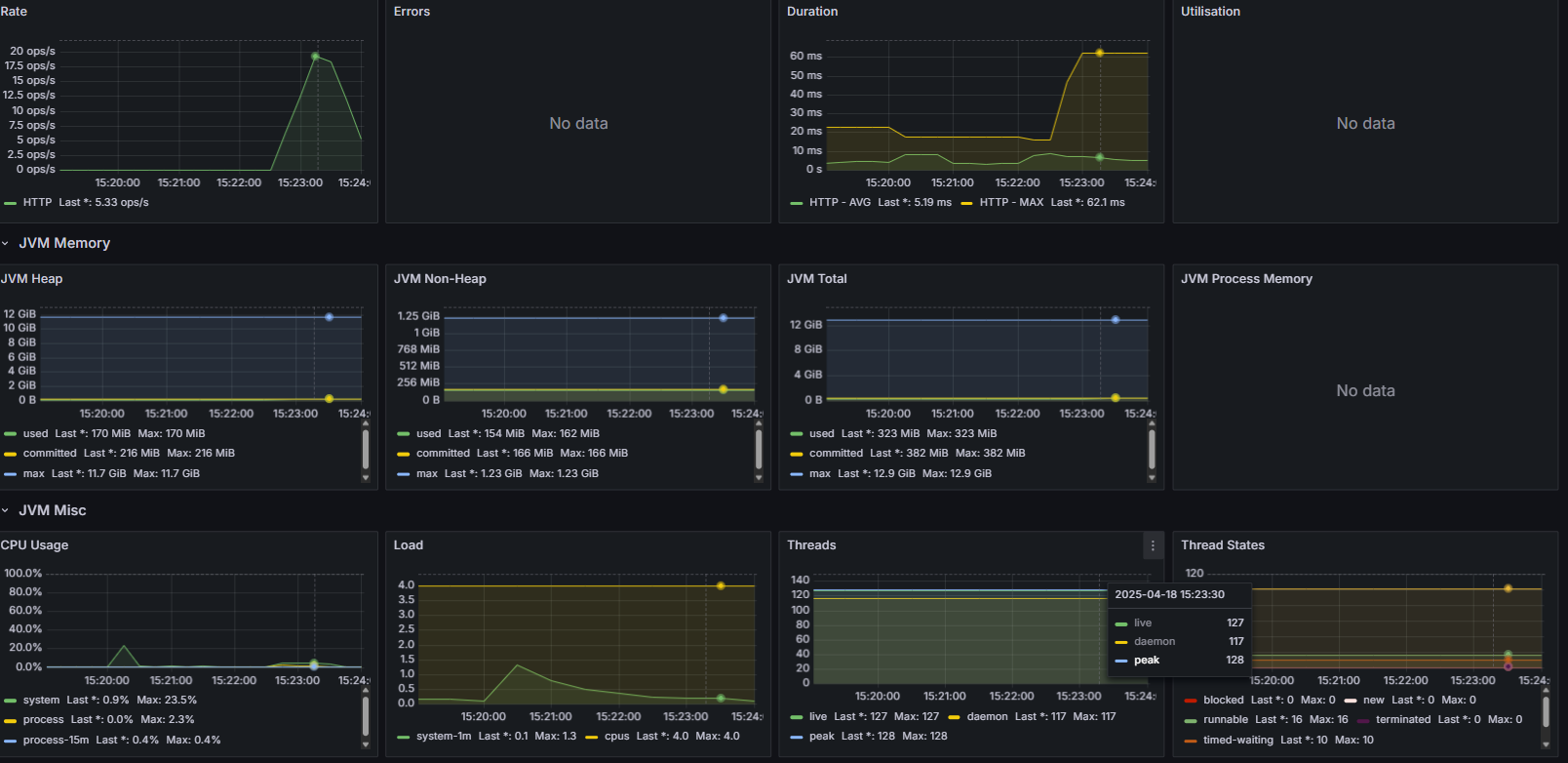
nGrinder의 detail report를 확인해보자

1분 28초에 모든 요청이 거부되기 시작했다.
에러 로그는 뭘까
2025-04-12 02:06:38,061 ERROR Connection refused: connect
java.net.ConnectException: Connection refused: connect
at HTTPClient.HTTPConnection.getSocket(HTTPConnection.java:3408)
at HTTPClient.HTTPConnection.sendRequest(HTTPConnection.java:3089)
at HTTPClient.HTTPConnection.handleRequest(HTTPConnection.java:2883)
서버로의 커넥션이 거부되었다.
그럼 해당 시간대에 어떤 이슈가 있었는지, 위에 있는 Grafana 모니터링 화면을 다시 보자
주의깊게 볼 점은 오른쪽 아래에 있는 Thread들의 상태이다.

요청은 계속해서 늘어나는데, 스레드는 200에서 멈춰서서 time waiting이 늘어나다가 급하강한다.
이걸로 미루어보아, 문제점은 Spring 서버의 Tomcat Thread수가 부족한 것으로 보인다.
Tomcat은 기본적으로 Thread 수를 200으로 설정해놓는다.
그래서 Tomcat의 Thread 수를 늘려줬다.
내 요구사항은 동시접속자 1000명을 거뜬하게 받아내야하기 때문에
application.properties에 Thread 관련 설정을 추가해준다.
#server
server.tomcat.threads.max=500
server.tomcat.max-connections=500
server.tomcat.accept-count=500
server.tomcat.connection-timeout=5000
server.tomcat.threads.min-spare=100
그럼 다시 테스트 해보자.
재테스트 결과는 생략하겠다
왜??
결과가 똑같다.....
똑같은 오류가 똑같이 발생한다.
그럼 내 문제 진단이 틀린걸까??
하지만 모니터링 결과와 로그 상으로 유추할 수 있는 문제점은 Thread 부족이 맞다.
그럼 뭐가 문제였을까
일단 나는 Docker에 모든 서비스를 올려놓고 테스트 하기 때문에, 내가 한 Tomcat 설정이 제대로 Docker container에 적용되었는지 확인을 해보아야했다.
그래서 tomcat의 로그를 찍어보았다.
import io.micrometer.core.instrument.MeterRegistry;
import org.apache.catalina.connector.Connector;
import org.apache.catalina.core.StandardThreadExecutor;
import org.apache.coyote.ProtocolHandler;
import org.apache.coyote.AbstractProtocol;
import org.springframework.boot.web.embedded.tomcat.TomcatServletWebServerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class TomcatMetricsConfig {
@Bean
public TomcatServletWebServerFactory tomcatFactory(MeterRegistry registry) {
return new TomcatServletWebServerFactory() {
@Override
protected void customizeConnector(Connector connector) {
super.customizeConnector(connector);
ProtocolHandler handler = connector.getProtocolHandler();
if (handler instanceof AbstractProtocol) {
StandardThreadExecutor executor = (StandardThreadExecutor) connector.getProtocolHandler().getExecutor();
registry.gauge("tomcat.threads.max", executor, StandardThreadExecutor::getMaxThreads);
}
}
};
}
}
결과는 적용이 되지 않고 있었다.
왜 Tomcat Thread 설정이 local 에서는 잘 적용이 되지만 Docker container 위에서는 적용이 잘 되지 않는걸까?
포인트는 Docker의 동작방식에 있었다.
Docker container는 VM처럼 내 local의 OS위에 가상머신과 비슷한 container를 올려서 구동시키는 방식이다.
따라서 사용할 수 있는 CPU와 메모리 등에 제한이 기본적으로 있기 때문에, 이에 대한 설정을 해주지 않는다면
내가 Thread 수를 아무리 늘리는 설정을 하더라도 container의 하드웨어적으로 받쳐주지 못하기 때문에
설정 적용이 되지 않는다.
따라서 Docker container를 올릴 때도 CPU 수와 메모리가 제한되지 않도록 설정해주자
아래는 Docker file에 관련 설정을 추가한 모습이다.
FROM eclipse-temurin:21-jdk-alpine
VOLUME /tmp
ARG JAR_FILE=build/libs/Triple_clone-0.0.1-SNAPSHOT.jar
COPY ${JAR_FILE} app.jar
ENTRYPOINT ["java", "-XX:+UseContainerSupport", "-XX:MaxRAMPercentage=75.0", "-XX:InitialRAMPercentage=50.0", "-XX:ActiveProcessorCount=4", "-Xss512k", "-jar", "/app.jar"]
가장 아래의 ENTRYPOINT에 추가했다.
각각의 설정이 뭘 의미하는지는 굳이 언급하지 않고 넘어가자, 구글링하면 바로 나오니...
Docker에 설정을 추가하고 다시 실행시켜보니 드디어 Thread 최대 수가 늘어났다.
이번에는 진짜 성공할 것 같다는 예상을 해보며, 다시 테스트를 해보았다.
재테스트 결과는 생략하겠다
왜??
또 결과가 똑같다.....^^^^^^^^^^^^^^
지금이야 문제를 다 해결했으니 블로깅을 하지만, 이때는 정말 멘탈이 깨질뻔 했다.
지금 이 글을 보는 누군가는 문제가 뭔지 예상할 수 있을지 궁금하다.
결론부터 말하자면 이번엔 MySQL connection의 부족이었다.
Thread의 수만 늘리니, 이번엔 그 많은 스레드들의 DB 조회 요청을 DB가 받아내지 못한 것이다.
그래서 바로 DB connection도 추가를 해주고 나니 드디어 해결되었다.
DB connection은 MySQL WorkBench에서 따로 늘려주었다, 기본이 151정도라 넉넉하게 1000으로 늘려줬다
여기서 중요한 점은
Tomcat Thread 수와 DB connection 수를 왜 500개 1000개로 설정했는가?
기준이 무엇인가?
아래에 내가 왜 그렇게 설정했는지에 대한 이유를 적어보았다.
실무에서 Tomcat의 Thread 수나 DB connection 풀 수 를 500, 1000 같은 큰 수치로 설정하는 이유는
단순히 "많이 받기 위해서"가 아니라, 시스템의 성능과 사용자 요구량을 기반으로 한 계산 및 여유 확보에 기반한다.
또한 Thread context switching 비용이 늘어나기 때문에, Thread 수가 많다고 항상 좋은 것도 아니다.
난 Thread를 점차 늘려가며, 300...400...500을 다 테스트 해 보았고, 요구사항을 맞추기 위해서는 Thread 수가 여유있게 500은 되어야 한다고 판단했고,
MySQL의 connection은 Spring thread가 500인데 왜 1000인가?
그러면 connection이 불필요하게 많은 거 아닌가 생각이 들 수도 있지만,
내 프로젝트에서 웹 스크래핑을 통해 MySQL에 저장하는 로직은 Spring 서버가 아니라 FastAPI 서버가 따로 작동하여 MySQL에 접근하고 있다.
즉, Spring에서만 MySQL에 접속하는 것이 아니기에 여유있게 1000으로 잡았다.
아래는 문제를 해결하고 다시 테스트 한 결과이다.
1. 동시 사용자 20명
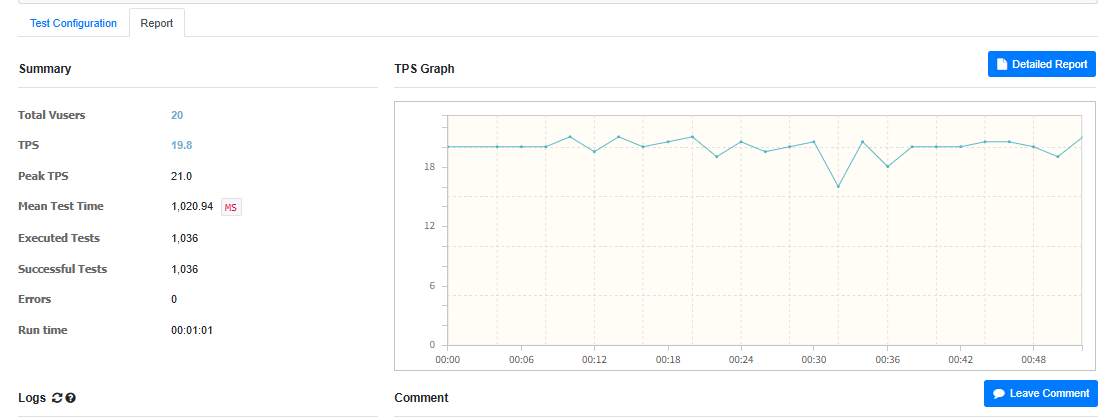
2. 동시 사용자 300명


3. 동시 사용자 1000명 (Ramp-up 형식으로 부하 테스트)

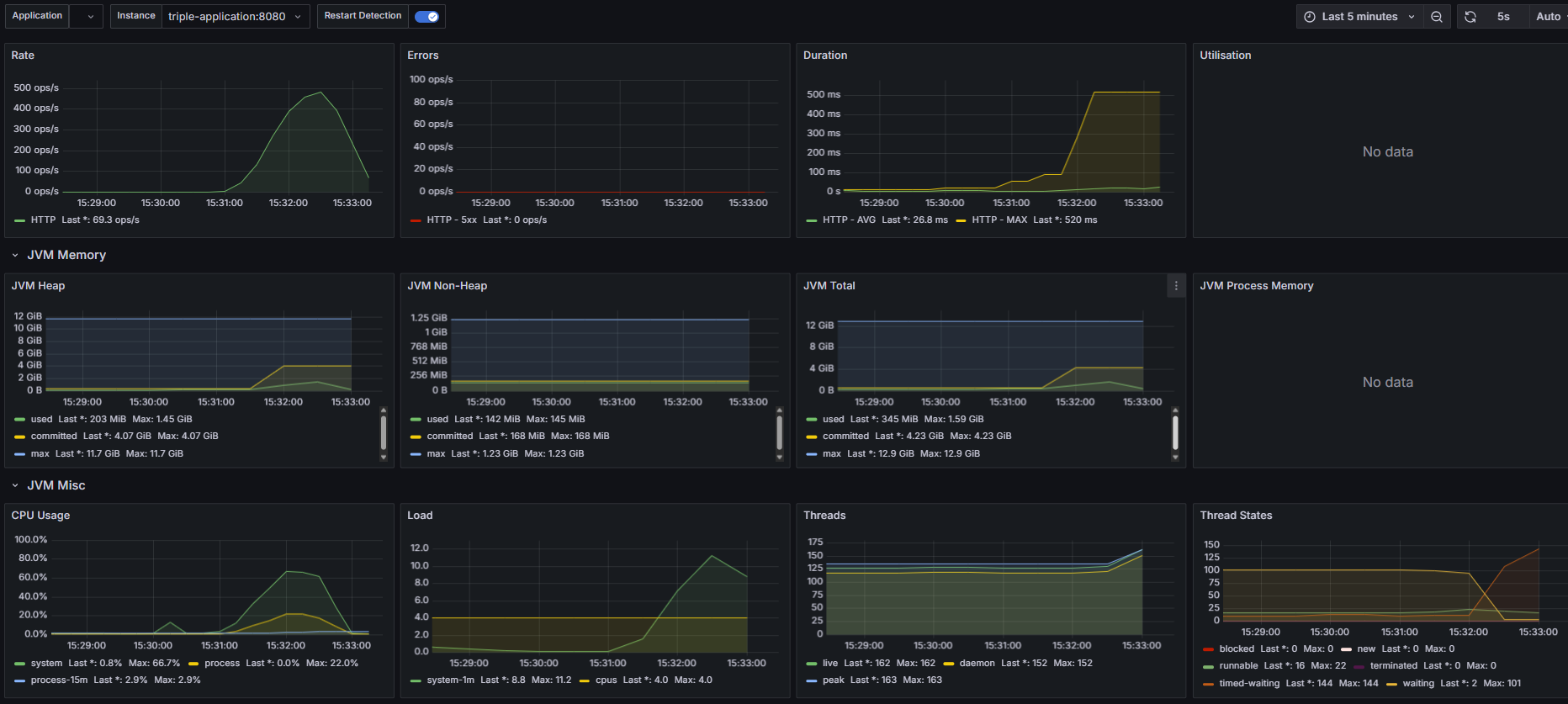
확실히 vuser를 1000명으로 잡고 한 테스트가 차이가 난다.
더이상 오류가 발생하지 않고 모든 요청을 다 잘 받아냈다.
그럼 이제 드디어 성능을 보자
내가 볼 지표는 크게 3가지로
- CPU 사용량
- TPS
- MTT
이 3가지를 볼 것이다.
동시 접속자가 20명일 때는 CPU사용량이 현저히 적어 성능 개선의 효과를 제대로 확인하지 못할 것 같기 때문에 무시하도록 하고,
동시 접속자가 300명 일 때
- CPU 사용량 (최대치) = 60%
- MTT = 1.079ms
- TPS = 278
동시 접속자가 1000명 일 때
- CPU 사용량 (최대치) = 66.7%
- MTT = 1.373ms
- TPS = 361
성능 개선
그렇다면 다시 성능 개선으로 돌아와서, 앞서 내가 말했듯이 난 현재 상황을 확인하고, 성능 개선의 목표치를 세워야 한다.
실제로 사용자들을 받아 현재 어느정도의 트래픽이 들어오고, 어떤 부분에 병목이 발생하는지를 보면 목표치를 세우는게 쉽겠지만,
난 상상으로 트래픽을 받았다고 치고 nGrinder로 테스트 한 것이기에ㅋㅋㅋㅋㅋㅋㅋ
동시 접속자가 300명가량이 꾸준히 숙소 조회를 한다고 가정하고 목표치를 세웠다.
목표치를 세울 때 나는 보통 평균 트래픽의 3배를 받을 때 어느정도의 성능을 내야할지를 고민한다.
300명의 3배가량인 1000명을 기준으로 잡고, 목표를 아래와 같이 잡았다.
성능 개선 목표
동시 접속자가 1000명일 때 MTT와 TPS는 준수하지만 CPU 사용량이 60% 이상으로 올라간다,
이는 다른 기능도 함께 사용될 때, CPU 과부하가 발생할 수 있기 때문에 낮출 필요가 있다.
따라서 CPU 사용량 감소를 최우선으로 생각한다.
1차 목표
- CPU 사용량를 40% 이하로 유지한다
- MTT 향상 (낮아져야 함)
- TPS 향상 (높아져야 함)
이렇게 목표를 설정했다면, 이제 성능 개선 방안을 생각해야 한다.
앞서 내가 생각한 성능 개선 방안은 3가지
- DB 인덱싱
- Redis 캐싱
- ES 도입
이 3가지다.
그렇다면 나에겐 어떤 방법이 잘 맞을지 고민해보자
아래는 각각의 장단점과 내 상황에 맞게 내가 ES를 선택한 이유이다.
✅ 1. 복합 인덱싱 (Composite Indexing)
✔ 장점
- RDBMS 본연의 기능: 별도 시스템 없이 DB 내부에서 해결 가능
- 데이터 일관성 보장: 트랜잭션, 정합성 걱정 없음
- 설정이 간단함: 복합 인덱스만 잘 설계하면 조회 성능 향상
❌ 단점
- 조건 순서 영향 큼: WHERE A=? AND B=?는 인덱스를 잘 타지만 WHERE B=? AND A=?는 못 탐
- 조합 폭발: 다중 필터 조건 조합이 많으면 인덱스도 무한대로 늘어나야 함
- LIKE, 범위 조건, 정렬이 복잡: 유연한 필터/검색 조건엔 한계
✅ 2. Redis 캐싱
✔ 장점
- 초고속 응답: 메모리 기반이라 매우 빠름 (ms 단위)
- 최근 인기 조건 캐싱: 자주 조회되는 조건 조합을 캐싱하면 효율적
- 간단한 구조: 캐시 키로 쿼리 조합을 쓰면 구현 쉬움
❌ 단점
- 캐시 키 폭발: 필터 조합 수가 많으면 캐시 저장/관리 어려움
- 데이터 변경시 갱신 어려움: Redis는 DB처럼 자동으로 최신화되지 않음
- 정렬/필터링 다양성 낮음: 캐시는 검색용이 아니라 ‘결과 저장’용
✅ 3. Elasticsearch 도입
✔ 장점
- 다양한 필터 + 정렬 + 검색에 최적화: 다중 조건, 부분검색, 범위검색, 스코어링 등 가능
- 빠른 검색 성능: 대량 데이터에서도 sub-second 응답
- 정렬/필터 유연함: 인덱스 하나로 다양한 조건 조합 대응 가능
- 분산 처리 기반 확장성: 대량 트래픽이나 데이터에도 확장 용이
❌ 단점
- 데이터 정합성 보장 안 됨: DB와 비동기 동기화 필요
- 복잡한 운영 필요: 클러스터 구성, 인덱스 설계, 매핑 관리 등 부담
- 쓰기 오버헤드 있음: 자주 변하는 데이터엔 부적합할 수 있음
🏆 결국 ES(Elasticsearch)를 선택한 이유
- 다중 조건 + 유연한 필터링이 핵심 요건이었고,
단순 RDB 인덱스로는 모든 경우를 커버하기 어려웠음 - LIKE 검색, 정렬, 범위조건 등 다양한 형태의 검색을 지원해야 했음
- 성능 측면에서 대량 데이터를 빠르게 처리할 수 있어야 했고,
ES는 인덱싱된 데이터를 기반으로 sub-second 응답을 제공함 - 향후 추천 시스템, 랭킹 기능, 유사 숙소 검색 등
검색 기반 확장을 고려할 때도 ES가 확장성에 유리
✍ 한 줄 정리
복합 인덱싱과 Redis 캐싱은 제한된 조건에서 성능 개선에 효과적이지만,
다중 조건과 유연한 검색 기능이 중요한 숙소 조회 서비스에서는
Elasticsearch가 구조적 유연성과 확장성 면에서 최적의 선택이었다.
위와 같은 이유로 나는 프로젝트에 ELK를 도입했고
기존에 querydsl을 사용하여 동적 쿼리를 생성하던 로직을 어떻게 처리하였는지만 보여드리고 나머지는 생략하겠습니다.
ES 동적쿼리 생성 코드
package com.example.Triple_clone.repository;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch._types.query_dsl.BoolQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.Query;
import co.elastic.clients.elasticsearch._types.query_dsl.QueryBuilders;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.search.Hit;
import co.elastic.clients.json.JsonData;
import com.example.Triple_clone.domain.entity.AccommodationDocument;
import lombok.RequiredArgsConstructor;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageImpl;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Repository;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
@RequiredArgsConstructor
@Repository
public class ESAccommodationRepositoryImpl implements ESAccommodationRepository {
private final ElasticsearchClient elasticsearchClient;
@Override
public Page<AccommodationDocument> searchByConditionsFromES(
String local, String name, String category, String discountRate,
String startLentPrice, String endLentPrice, String score,
String lentStatus, String startLodgmentPrice, String endLodgmentPrice,
String enterTime, String lodgmentStatus, Pageable pageable) {
List<Query> mustQueries = new ArrayList<>();
if (local != null && !local.isEmpty()) {
mustQueries.add(QueryBuilders.term(t -> t.field("local.keyword").value(local)));
}
if (name != null && !name.isEmpty()) {
mustQueries.add(QueryBuilders.match(m -> m.field("name").query(name)));
}
if (category != null && !category.isEmpty()) {
mustQueries.add(QueryBuilders.term(t -> t.field("category.keyword").value(category)));
}
if (score != null && !score.isEmpty()) {
mustQueries.add(QueryBuilders.range(r -> r.field("score").gte(JsonData.of(Double.parseDouble(score)))));
}
if (enterTime != null && !enterTime.isEmpty()) {
mustQueries.add(QueryBuilders.range(r -> r.field("enter_time").gte(JsonData.of(enterTime))));
}
if (discountRate != null && !discountRate.isEmpty()) {
long dr = Long.parseLong(discountRate);
mustQueries.add(QueryBuilders.bool(b -> b
.should(QueryBuilders.range(r -> r.field("lodgment_discount_rate").gte(JsonData.of(dr))))
.should(QueryBuilders.range(r -> r.field("lent_discount_rate").gte(JsonData.of(dr))))
.minimumShouldMatch("1")
));
}
if (startLentPrice != null && !startLentPrice.isEmpty()) {
mustQueries.add(QueryBuilders.range(r -> r.field("lent_price").gte(JsonData.of(Long.parseLong(startLentPrice)))));
}
if (endLentPrice != null && !endLentPrice.isEmpty()) {
mustQueries.add(QueryBuilders.range(r -> r.field("lent_price").lte(JsonData.of(Long.parseLong(endLentPrice)))));
}
if (lentStatus != null && !lentStatus.isEmpty()) {
mustQueries.add(QueryBuilders.term(t -> t.field("lent_status").value(Boolean.parseBoolean(lentStatus))));
}
if (startLodgmentPrice != null && !startLodgmentPrice.isEmpty()) {
mustQueries.add(QueryBuilders.range(r -> r.field("lodgment_price").gte(JsonData.of(Long.parseLong(startLodgmentPrice)))));
}
if (endLodgmentPrice != null && !endLodgmentPrice.isEmpty()) {
mustQueries.add(QueryBuilders.range(r -> r.field("lodgment_price").lte(JsonData.of(Long.parseLong(endLodgmentPrice)))));
}
if (lodgmentStatus != null && !lodgmentStatus.isEmpty()) {
mustQueries.add(QueryBuilders.term(t -> t.field("lodgment_status").value(Boolean.parseBoolean(lodgmentStatus))));
}
BoolQuery boolQuery = new BoolQuery.Builder()
.must(mustQueries)
.build();
try {
SearchResponse<AccommodationDocument> response = elasticsearchClient.search(
s -> s.index("accommodation")
.query(q -> q.bool(boolQuery))
.from((int) pageable.getOffset())
.size(pageable.getPageSize()),
AccommodationDocument.class
);
List<AccommodationDocument> results = response.hits().hits().stream()
.map(Hit::source)
.collect(Collectors.toList());
long total = response.hits().total() != null ? response.hits().total().value() : results.size();
return new PageImpl<>(results, pageable, total);
} catch (IOException e) {
throw new RuntimeException("Elasticsearch 검색 중 오류 발생: " + e.getMessage(), e);
}
}
}
그럼 거두절미 하고 ES를 도입한 후 성능 테스트 결과를 보여드리자면
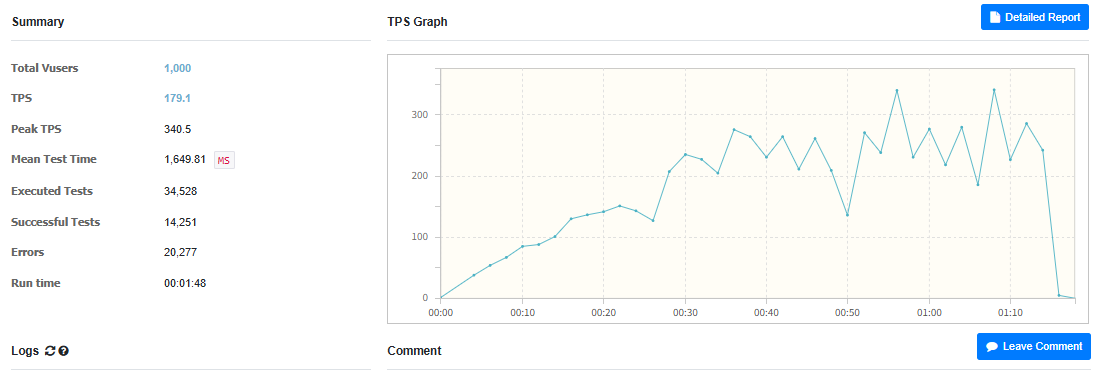
이게 무슨 일인지ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
ES를 도입했더니 성능이 더 안좋아졌다.
하지만 딱 보니 느낌이 온다.
아까봤던 그래프다
요청을 받다가 특정 구간에서 모든 요청이 실패한다.
이를 보자마자 난 알았다 ES connection이 부족하다는 것을
그래서 바로 ES 커넥션을 아래와 같이 늘려주었다^^
@Configuration
public class ElasticSearchConfig {
@Bean
public RestClient restClient() {
String username = "logstash_internal";
String password = "logstashPw";
String auth = username + ":" + password;
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes(StandardCharsets.UTF_8));
BasicHeader authHeader = new BasicHeader(HttpHeaders.AUTHORIZATION, "Basic " + encodedAuth);
RestClientBuilder builder = RestClient.builder(new HttpHost("elasticsearch", 9200))
.setDefaultHeaders(new BasicHeader[]{authHeader});
return builder.setHttpClientConfigCallback(httpClientBuilder ->
httpClientBuilder
.setMaxConnTotal(500)
.setMaxConnPerRoute(500))
.build();
}
아래에
.setMaxConnTotal(500)
.setMaxConnPerRoute(500))
이 부분이 ES의 connection을 늘려주는 부분이다.
근데 이상한 점이 있었다.
보통 connection이 부족하면 잘 실행되다가 갑자기 요청이 전부 거절되는데,
이번 케이스는 계속 꾸준히 오류가 발생한 것처럼 보였다.
그래서 log를 확인해봤다.
java.lang.NullPointerException: Cannot invoke "java.lang.Long.longValue()" because the return value of ...
역시나.....처음 보는 오류 로그가 발생했다.
천천히 로그를 읽어보니, ES에서 데이터를 가져올 때 값이 없는 경우 null로 가져오는데, 이를 기본 타입에 넣을 수 없어서 NPE가 발생한다는 오류였다.
그렇다면 해결방법은 2가지
- ES에 데이터를 넣을 때 null이 아닌 기본값 설정해서 넣어주기
- ES에서 데이터 가져올 때 null이면 기본값 넣기
나는 2번째 방법을 선택했다.
왜냐하면 ES에 데이터를 넣는 과정은 수천 수만개의 데이터를 처리해야하는 이벤트인데, 여기에 로직을 하나 더 얹을바엔
DTO에서 ES에서 가져온 데이터를 파싱할 때 기본값을 넣어주는게 훨씬 더 간편하다고 판단했기 때문이다.
그래서 ES document (ES용 Entity)를 DTO로 바꾸는 과정을 아래와 같이 수정해주었다.
public AccommodationDto(AccommodationDocument document) {
this(
document.getLocal(),
document.getName(),
document.getScore() != null ? document.getScore() : 0.0,
document.getCategory(),
document.getLentDiscountRate() != null ? document.getLentDiscountRate() : 0L,
document.getLentTime() != null ? document.getLentTime() : 0,
document.getLentOriginPrice() != null ? document.getLentOriginPrice() : 0L,
document.getLentPrice() != null ? document.getLentPrice() : 0L,
document.getLentStatus() != null ? document.getLentStatus() : false,
document.getEnterTime() != null ? document.getEnterTime() : "",
document.getLodgmentDiscountRate() != null ? document.getLodgmentDiscountRate() : 0L,
document.getLodgmentOriginPrice() != null ? document.getLodgmentOriginPrice() : 0L,
document.getLodgmentPrice() != null ? document.getLodgmentPrice() : 0L,
document.getLodgmentStatus() != null ? document.getLodgmentStatus() : false
);
}
아래는 ES 커넥션을 늘려주고, NPE도 해결한 다음의 결과다
ES 도입 후 성능


성능 개선 전과 비교했을 때,
CPU 사용량이 60%대에서 40% 이하로 향상되었으며,
MTT는 1.373 에서 1.351로 거의 변화를 안보였으며,
TPS는 370으로 거의 변화가 없었지만 둘 다 향상된 모습은 보였다.
후기
솔직히 말로만 듣던 ElasticSearch를 사용해보는 경험에 엄청난 성능 향상을 기대했다.
하지만 결과는 CPU 사용량이 좀 줄었을 뿐, MTT와 TPS가 거의 변화가 없는걸 보고 실망하지 않을 수 없었다
찾아보니 ES는 데이터가 수십만건에 달할 정도로 많아야 눈에 띄는 성능 향상이 보이고,
수천 수만건의 데이터에는 MySQL + Querydsl을 사용하며 MySQL + 인덱스 튜닝이 더욱 효과적일 수 있다고 한다.
그래도 ES를 통해 성능 개선 목표는 달성하였으니, 일단 다음 기능 구현으로 넘어가되
ES 튜닝, Redis 캐싱등을 사용한 2차 성능 개선을 염두해 두어야 겠다.
+ 숙소 데이터를 MySQL과 ES를 동기화 해주어야하는 포스팅을 작성해야겠다......
두서없는 긴 글 읽어주셔서 감사합니다.
'백엔드 멘토링' 카테고리의 다른 글
| 인스타그램이 우리들의 관심사를 알아내는 방법 (1) | 2025.08.22 |
|---|---|
| 카카오 T 에서 최단거리를 탐색하는 방법 (3) | 2025.08.21 |
| [회고록] Stock-simulation 프로젝트 API 완성도 기록지 (1) | 2024.12.20 |
| 주식 프로젝트 influx DB 도입 ADR 과정 (0) | 2024.10.30 |
| [회고록] Nomadic 프로젝트 API 완성도 기록지 (3) | 2024.09.28 |