이번에는 저번 좋아요 기능 성능 개선해보기(1)에 이어서 리팩터링을 해보고자 한다.
저번 리팩터링에서 기존 하나의 요청마다 DB에 좋아요(좋아요 취소) 쿼리를 전송하여 사용자가 많이짐에 따라 DB 커넥션도 증가하면서 DB 부하가 너무 크게 걸리는 것을 해결하고자 하였고,
나는 좋아요 요청을 따로 local의 Map에 임시 저장 시켜놨다가 Spring Batch를 사용하여 5초마다 DB에 벌크 업데이트 시켜주도록 리팩터링을 진행하여 TPS 2.5배 향상, MTT 81%감소 라는 개선을 하였다.
하지만 이는 Map연산이 추가됨에 따른 리소스를 생각해보니 너무 많은 자원을 사용하지 않을까 싶었고,
다른 사람들 혹은 기업은 어떻게 좋아요를 구현했고, 어떤 방식으로 개선하였는지 궁금해졌다.
먼저 말하자면, 다른 사람이나 기업에서의 좋아요 구현에 대해 많은 구글링을 해보고 기술 포스팅도 봤지만,
거의 대부분이 나와 같은 고민은 거의 하지 않고 동시성 문제 혹은 조회 쿼리 성능 개선에 대한 글들이 많았다.
내 코드에서도 게시물들을 조회하여 올 때 너무 많은 쿼리들이 날아가기에, 개선을 할 필요가 있었지만,
지금 내가 해결하려는 문제는 아니었기에 다른 코드와의 비교는 별 수익이 없었다.
다음으로는 Map연산에 대한 추가 리소스 사용이다.
나는 리팩터링한 내 코드가 기존의 코드보다 얼마나 더 많은 리소스를 사용하는지 알아보기 위해
모니터링 툴들을 적용했다.
내가 선택한 모니터링 툴들은
- Spring Actuator
- Prometheus
- Grafana
이 3가지를 사용하였고. 모두 Docker에 올려서 사용하였다.
많은 모니터링 툴 중 이 3가지를 선택한 이유는 여러가지 모니터링 툴들이 존재하지만, 어차피 모니터링을 위해 Spring Actuator로 매트릭을 수집해야 한다면, Spring 모니터링에 가장 많이 사용되고 있는 Prometheus와 Grafana를 사용하자는 마음이었다. 이 조합이 가장 많이 사용하고 많은 정보들이 있었으며, 그렇기에 신뢰하고 이미 보증된 모니터링 방법이라 생각했기 때문이다.
그렇게 모니터링 툴들을 Docker를 사용하여 띄운뒤에 초기 리팩터링 하기전의 코드부터 테스트 해보았다.
nGrinder를 사용하여 vuser는 500명으로 3분간 테스트를 진행하였을 때,

중간에 조금 잘렸지만 평균적으로 약 3~5%정도만 사용되고 있다. 하지만 이는 CPU사용량일 뿐 내 DB에는 엄청난 부하가 가고 있을 것이다.
그 다음은 벌크 업데이트 연산 리팩터링 후이다. nGrinder 테스트 환경은 동일하게 진행했으며

예상했던 것과 같이 CPU 사용량이 약 40%까지 올라간 것이 확인 되었다.
물론 TPS와 MTT면에서는 성능이 많이 개선이 되었지만, 내 프로젝트에서 좋아요 기능 자체는 그렇게 중요한 기능을 담당하지 않는데 CPU를 이렇게나 많이 사용해버리면 문제가 된다.
따라서 이제 CPU 사용량을 줄여야만 하였는데, 이를 어떻게 해결할지 고민해 본 결과
- Map연산 성능 개선하기
- 아예 다른 알고리즘을 사용하기
- 스케일 아웃 or 스케일 업
- 트래픽 제한하기
이 세가지 방안이 떠올랐다.
하지만 Map연산 성능을 개선하려고 정말 많이 노력하고 고민해봤지만, 도저히 방법을 찾을 수 가 없었다....
Map연산 자체가 문제가 아니라 Collection자체를 사용하는데 리소스가 많이 소요되는 터라 Collection이 아닌 다른 방법을 생각해 내야 했던 문제였기에 1번 해결방안은 포기하였다.
1번 해결방안을 포기하고 2번을 고민해보며, 다른 사람들이 좋아요 기능을 어떻게 구현하였는지 다시 한번 많이 찾아보았다. 하지만 많은 블로그들을 보아도 대부분이 내 초기의 코드와 같은 방식으로 하나의 요청에 대해 하나의 쿼리를 보내도록 구현하였고, 가끔 벌크 연산을 통해 내 리팩터링된 코드와 비슷하게 구현한 코드들을 볼 수 있었다.
그래서 다른 사람들의 구현 방식을 찾는 것을 포기하고 나 스스로 어떻게 바꿔야 연산 기능이 좋아질지 고민해봤지만....
내겐 너무나도 어려운 문제였다..
그렇게 2번 방법도 포기하고 3번 방법을 생각해보았다.
사실 혼자 진행하는 토이 프로젝트에서 스케일 업이란 거의 불가능에 가까웠기에, 스케일 아웃을 통해 따로 좋아요 요청을 받는 서버를 만들어서 로드 밸런싱을 한다면, 저렇게 CPU사용량이 높아도 상관없지 않을까 싶었지만, 과연 내 프로젝트에서 좋아요 기능이 스케일 아웃을 해줄 만큼 중요한 기능인가? 에 대한 의문이 들었다.
좋아요 기능은 사실 있어도 그만 없어도 그만인 기능인지라 이 성능을 개선 시켜주기 위해 추가적인 비용을 들여서 스케일 아웃을 해주는 것 또한 배보다 배꼽이 더 큰 느낌이기에 포기하였다.
마지막으로 트래픽을 제한하여 CPU사용량을 낮춰주는 방법이다.
사실상 좋아요 기능은 바로바로 처리가 되지 않아도 큰 문제가 없는 기능이다, 즉 많은 요청이 와도 이들을 제한된 요청만 초당 처리하도록 하고 그 이외의 초과된 요청들에 대해서는 대기시켰다가 순차적으로 요청을 수행해도 특별한 문제가 없을 것 같다고 생각했다.
난 트래픽을 제한시키기로 마음 먹었고 목표치를 설정해야 했다.
일전에 성능 개선을 시킬 때는 목표 성능 없이 무작정 성능 개선을 시켰는데, 이렇게 목표 요구사항을 정리하지 않은 상태에서 성능 개선을 해버리면 정말 끝이 없어 보였기에 이번엔 목표 요구사항을 정리해서 성능 개선을 해보고자 한다.
성능 개선 요구사항
- 평소 사용자는 500명이다.
- 이벤트로 인한 사용자가 3000명까지 들어올 것으로 예상된다.
- 이벤트를 진행할 때나 평소에 TPS를 500, CPU사용률을 10%를 유지하고자 한다.
- 이를 위해 예상치의 3배인 9000명으로 테스트를 진행하여 성공시키자.
나는 2000인 TPS를 500으로 줄이기 위해 처리율 제한 툴을 사용하였다.
많이 사용되는 처리율 제한 장치에는
- Guava
- RESILIENCE4J
- RATE LIMIT J
- Bucket4J
이 4가지가 존재하는 것 같은데, 각각의 특징을 알아보며 나에게 적절한 처리율 제한 장치를 선택해보자.
첫번째 Guava 같은 경우에는 처리율 제한을 목적으로 나온 라이브러리가 아니기 때문에 선택하지 않았다.
두번째 RESILIENCE4J는 MSA에서 많이 사용된다고 하던데, 자세히는 알아보지 않았고, 나는 MSA가 아니기에 선택하지 않았다.
세번째 RATE LIMIT J 같은 경우에는 더이상 서비스 하지 않으니 Bucket4J을 사용하라고 되어 있기에 네번째 Bucket4J을 선택했다.
이 외에도 처리율 제한 알고리즘들도 많이 있었지만 너무 하나하나 읽으며 이해하고 하기에는 너무 처리율 제한에 대해 깊게 들어가는 것 같아서 뭐가 있는지 알아만 두자.
- 토큰 버킷 알고리즘
- 누출 버킷 알고리즘
- 고정 윈도 카운터 알고리즘
- 이동 윈도 알고리즘
- 이동 윈도 카운터 알고리즘
이들 중 내가 선택한 Bucket4J에서 사용하는 알고리즘은 토큰 버킷 알고리즘이었다.
내 프로젝트에서 Bucket4J를 사용하기 위해 의존성을 먼저 build.gradle에 추가해 주었다.
implementation 'com.bucket4j:bucket4j-core:8.3.0'
그 다음 얼마 주기로 얼마나 처리할 것인지에 대한 Config를 작성하였다.
@Configuration
public class BucketConfig {
@Bean
public Bucket bucket() {
Refill refill = Refill.intervally(500, Duration.ofSeconds(1));
Bandwidth limit = Bandwidth.classic(500, refill);
return Bucket.builder()
.addLimit(limit)
.build();
}
}
위의 코드는 1초마다 500개의 요청만 처리하겠다는 코드이며 1초마다 이 커넥션들이 리필되도록 설정하였다.
마지막으로 이 config를 특정 api에 적용 시키기 위해 AOP를 이용하였다.
@Aspect
@Component
@RequiredArgsConstructor
public class RateLimitAspect {
private final Bucket bucket;
@Pointcut("@annotation(org.springframework.web.bind.annotation.PutMapping) && execution(* com.example.Triple_clone.web.controller.recommend.user.RecommendController.like(..))")
public void likeMethod() {
}
@Around("likeMethod()")
public Object rateLimiting(ProceedingJoinPoint joinPoint) throws Throwable {
if (bucket.tryConsume(1)) {
return joinPoint.proceed();
} else {
throw new IllegalArgumentException("request pull exceed");
}
}
}
이를 통해 나는 좋아요 기능에만 처리율 제한을 적용하였고, 이를 3000명의 vuser로 테스트 해본 결과
1초만에 테스트에 실패했다..
그 이유는 내 좋아요 기능은 초당 500개의 요청만을 처리할 수 있는데 vuser 3000명으로 테스트를 하다 보니 1초에 엄청난 수의 요청이 날라가서 500개를 제외한 모든 요청이 오류가 나버린 것이다.
그래서 vuser를 1명으로 두고 다시 테스트를 해보니
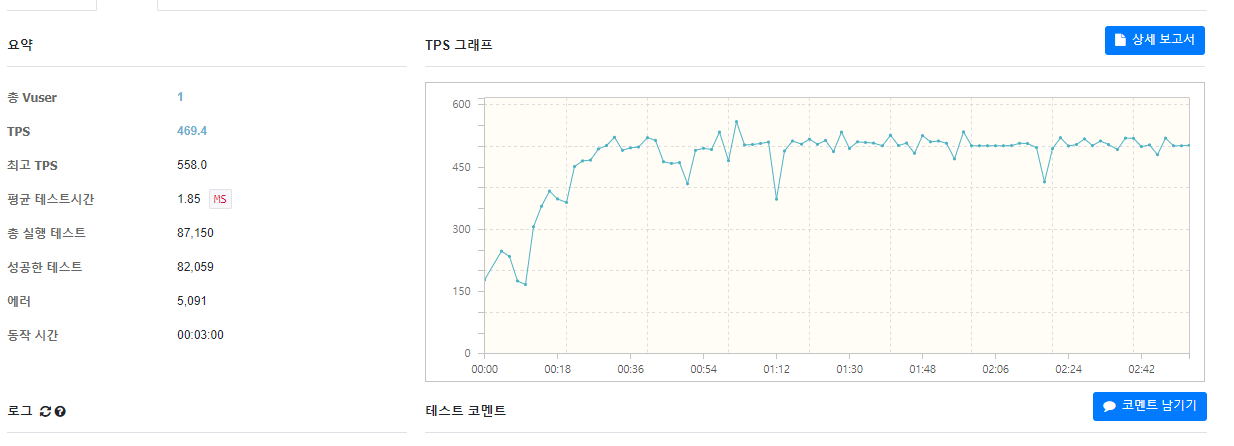
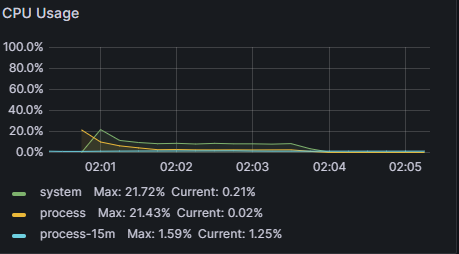
정확히 내가 원하던 결과값이 나왔다. TPS는 500이며, CPU사용량은 10%이다.
하지만 나는 vuser가 9000명일 때 이런 결과값을 원했기에, 요청이 초과되었을 때 예외를 발생시키는 것이 아닌 다른 방법을 생각해내야했고, 나는 대기 큐에 모든 초과된 요청을 넣으면 되지 않을까 라고 생각했다.
Spring application의 내장 톰캣은 이미 요청 큐를 가지고 있으며 내가 알기로는 기본 200개의 스레드와 100크기의 대기 큐를 가지고 있는것으로 알고있다.
그렇다면 이 대기 큐의 크기를 매우 크게 늘리면 해결될 일이었지만, 모든 것이 그렇듯 이또한 트레이드 오프이다.
대기 큐를 무작정 크게 늘린다면, 지금 내가 해결하고자 하는 문제는 해결되겠지만, 그 대기 큐의 크기만큼 메모리를 사용하게 되는 것이다.
vuser를 1명으로 했을 때도 약 9만개의 요청이 3분안에 들어왔는데 vuser가 9000명이라면 몇개의 요청이 들어올까
분명 몇천만개의 요청이 들어올 것이라고 예상된다.
그럼 내 대기 큐도 몇천만은 거뜬히 받을 수 있도록 설정해야 한다는 것인데, 이건 좋아요 기능의 중요도에 비해 너무 큰 메모리 낭비라고 생각되었다.
이 외에도 현재 좋아요 요청시 이미 좋아요를 누른 상태라면 좋아요 취소 쿼리, 아니라면 좋아요 쿼리를 날리도록 로직을 작성했는데 이를 분리시킨다면 해당 api로의 요청이 매우 줄어들 것이고, insert와 delete를 나눔으로써 좀 더 restful한 api를 만들 수 도 있다는 생각을 했다.
하지만 결국 나는 이를 해결하지 못하였다....
그래도 3분에 요청이 9만개가 들어왔을 때 내가 원하는 결과값이 나왔다!
사실 좋아요 기능은 메인 기능이 아니기에 나는 이정도 성능 개선에도 만족한다.
이를 계기로 여러 모니터링 툴과 처리율 제한 장치를 써볼 수 있는 기회가 있었고, 이 성능 개선만 거의 2주째 잡고 있었던 터라 여기서 더 고민하고 개선하는 행동은 아깝다는 생각이 크게 들어서, 좋아요 기능에 대한 성능 개선은 여기서 마무리 하고 남은 기능을 마저 개발해야겠다.
'백엔드 멘토링' 카테고리의 다른 글
| 객체지향적 Refactoring 과정의 기록 (1) | 2024.07.11 |
|---|---|
| 순환 참조를 해결해보기 (0) | 2024.02.28 |
| 좋아요 기능 성능 개선해보기 (1) (1) | 2024.02.16 |
| @OneToMany, @ElementCollection (1) | 2023.12.01 |
| 단축 url 서비스 Base62으로 리팩터링하기 - 회고록 (1) | 2023.10.08 |